
When I started learning Kubernetes, I had following questions in my mind
- Whats inside a Kubernetes cluster?
- How does it manages deployment and scaling?
- How to create and deploy application on the cluster?
In this blog we will look at a very simplified view of how does a Kubernetes cluster looks likes, and what are its different components. In the other blogs of this series we will see how to create K8s cluster on local or cloud, and how to deploy applications on it.
1.0 High Level Overview of k8s architecture
Kubernetes is an orchestrator of containerized cloud-native apps
A containerized application is an app that runs in a container (e.g. docker container)
A cloud-native application is an application that is designed to meet modern business demands (auto-scaling, self-healing, rolling updates etc.)
So basically Kubernetes is an application orchestrator that can do following
- Deploy the applications and also respond to changes.
- Scale it up and down based on demand.
- Self heal when things break down.
- Perform zero-downtime upgrades and rollbacks.
The most simplistic view of a cluster is as below – which shows where our application container actually gets deployed.

Apart from the worker nodes, the cluster also has a control plane – that manages the entire cluster.
This is how a typical Kubernetes cluster would look like

Let’s look at each component in detail – one by one.
2.0 Master Node / Control Plane
The Control Plane runs various services that is responsible for managing of a Kubernetes cluster.
It consists of
- API Server
- Cluster Storage (etcd)
- Scheduler
- Controller Manager
- Cloud Controller Manager
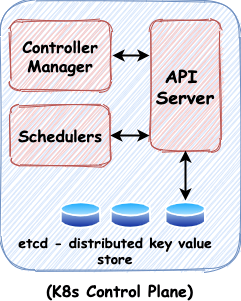
2.1 API Server
- It exposes Kubernetes API over REST.
- We can send POST requests to API server with Yaml configuration files (also called as manifest)
- The Yaml manifest contains information about the desired state of the application
- which image to deploy
- how many replicas needed
- which ports to expose, etc
- All requests to the API Server are subject to authentication and authorization checks
- Once the configuration is validated by the API server, it is persisted in the cluster storage and required changes are made to the cluster.
So basically API Server is the only entry point – by which we can communicate to the cluster.
In fact all worker nodes also communicate with the control plane, via the API server.
2.2 Cluster Storage (etcd)
- It is the only stateful part of the control plane.
- It store all the configuration, and the desired state of the cluster.
- Without this storage, there would not be a cluster.
- Kubernetes uses etcd as the backing store for all cluster data
etcdis a distributed, reliable key-value store.etcdprefers consistency over availability – this means that it will not tolerate a split-brain situation and will halt updates to the cluster in order to maintain consistency.- it uses the popular RAFT consensus algorithm to maintain the consistency of writes to the storage
2.3 Scheduler
- The scheduler watches the API server for newly created
podswith no assignednodes, and assigns them to appropriate healthy nodes. - How does the scheduler decide which node to run the pod on?
- First it identifies the nodes that is capable of running the pod, based on different checks
- is the node tainted
- are there any affinity or anti-affinity rules
- is the required network port available on the node
- does the node have sufficient free resources etc.
- Once all capable nodes are identified, it then ranks the nodes based upon criteria like
- does the node already have the required image
- how much free resource does the node have
- how many tasks is the node already running.
- The node with highest ranking is chosen to run the pod.
- First it identifies the nodes that is capable of running the pod, based on different checks
2.4 Controller Manager
- The controller manager implements all of the
background control loops, that monitor the cluster and respond to events – this logic is the heart of Kubernetes and declarative design pattern. - It’s a controller of controllers, meaning it spawns all of the independent control loops and monitors them. e.g.
- Node controller
- Endpoints controller
- ReplicaSet controller, etc
- Each controller runs a
background watch loopconstantly and watches the API Server for changes, and ensures that the current state of the cluster matches the desired state. - The logic implemented by each controller is as simple as this
- Obtain desired state from API Server (what we want from the cluster)
- Observe current state of the cluster (what we have currently in the cluster)
- Determine differences between desired state and current state
- Reconcile differences

Kubernetes works in
Declarativemodel – we only tell what we want, but not how to achieve it.
e.g we tell Kubernetes to run 2 replica of given application image and expose port 9000 – this is ourDesired state.
But we never tell how to deploy the application, or how create the replicas or expose the ports, etc.This is very different from
Imperativemodel, where we have to write a long list of commands on how to achieve the desired state, and system just runs the command to achieve desired state.
Let us consider a simple scenario
- Cluster is currently running 2 replicas of application (V1.0), and has exposed port 8080
- Current State
- Replica = 2
- Port exposed = 8080
- Application image version = V1.0
- Current State
- Now suppose we want to scale up our application to 4 replicas.
So we post a YAML configuration file to API Server- Desired State
- Replica = 4
- Port exposed = 8080
- Application image version = V1.0
- Desired State
- ReplicaSet controller manager identifies that there is difference between the desired and current state, and it will take action and spawn up 2 more pods of the application.
2.5 Cloud Controller Manager
- If the cluster is running on a supported public cloud platform, such as AWS, Azure, GCP, etc. the control plane will be running a Cloud Controller Manager.
- Its job is to manage integrations with underlying cloud technologies and services such as instances, load-balancers, and storage.
- For example, if the application asks for an internet facing load-balancer, the cloud controller manager is involved in provisioning an appropriate load-balancer on the cloud platform.
- This manager will not be present, if the Kubernetes cluster is hosted in an on-premise deployment, or if you are running a local cluster (e.g. using minikube, kind, etc)
3.0 Worker Nodes
A node may be a virtual or physical machine, depending on the cluster.
At high level node does following
- Watch API server for new work assignments.
- Execute work assignment within pods.
- Report back to the control plane (via the API server).
Main components of nodes are
- Kubelet
- Container runtime
- Kube Proxy
- Pods

3.1 Kubelet
- It’s the main Kubernetes agent that runs on every node in the cluster.
- When we add a new node to the cluster, a
kubeletis installed automatically on the node. - Kubelet is responsible for following
- Registering the node with the cluster – which effectively pools the node’s CPU, memory, and storage into the wider cluster pool.
- Watch the API server for new work assignments.
- Any time it sees one, it executes the task and maintains a reporting channel back to the control plane.
- If a kubelet can’t run a particular task, it reports back to the master and lets the control plane decide what actions to take.
3.2 Kube-Proxy
- This runs on every node in the cluster and is responsible for local cluster networking.
- e.g. it makes sure each node gets its own unique IP address, and implements local IPTABLES or IPVS rules to handle routing and load-balancing of traffic on the Pod network.
3.3 Container runtime
- The Kubelet needs a container runtime to perform container-related tasks-–things like pulling images and starting and stopping containers.
- In the early days, Kubernetes had native support for a few container runtimes such as Docker.
- More recently, it has moved to a plugin model called the
Container Runtime Interface (CRI).- At a high-level, the CRI masks the internal machinery of Kubernetes and exposes a clean documented interface for 3rd-party container runtimes to plug into.
- There are lots of container runtimes available for Kubernetes. One popular example is
cri-containerd.
3.4 Pod
Virtualization does VMs, Docker does containers, and Kubernetes does Pods.
- Pods is smallest unit of deployment in Kubernetes, and is used to deploy applications.
- Pod is a shared execution environment for one or more containers.
- Shared execution environment means that the Pod has a set of resources that are shared by every container that is part of the Pod.
- These resources include; IP addresses, ports, hostname, sockets, memory, volumes, etc.
- The simplest model is to run a single container per Pod.
- However, there are advanced use-cases that run multiple containers inside a single Pod. e.g.
- Service meshes
- Web containers supported by a helper container that pulls the latest content
- Containers with a tightly coupled log scraper
- Each Pod creates its own network namespace.
- This includes; a single IP address, a single range of TCP and UDP ports, and a single routing table.
- If a Pod has single container, that container has full access to the IP, port range and routing table.
- If it’s a multi-container Pod, all containers in the Pod will share the IP, port range and routing table.
4.0 Kubernetes DNS
- Every Kubernetes cluster has an internal DNS service.
- The cluster’s DNS service has a static IP address that is hard-coded into every Pod on the cluster, meaning all containers and Pods know how to find it.
- Every new service is automatically registered with the cluster’s DNS so that all components in the cluster can find every Service by name.
5.0 Kubernetes Objects
Kubernetes objects OR K8s API Resources – are the persistent entities in the k8s system, and they represent the state of the cluster.
Some of the important objects are

We will not go into details of each one of them now, and will look into them in our future blogs.
