

In our previous blog, we looked at how to implement caching in Spring Boot using Caffeine cache. In current blog we will start by looking at some problems of caching in an distributed environment (more than one nodes of same application server), and later we will look at how to implement distributed caching in Spring Boot applications using Hazelcast cache.
1.0 Why caching is difficult in an distributed environment
Suppose you have an environment like this below – Multiple nodes of same Spring Boot application running with embedded cache (e.g Caffeine cache)

Now each application server will have its own copy of cache, but will share a common database.
If there is any request to update any record in database, then only the cache of the application server that handles the request will updated after the operation. All other caches on all other application server nodes will still continue to serve stale data.
Lets look at a sample scenario with 2 application server nodes.
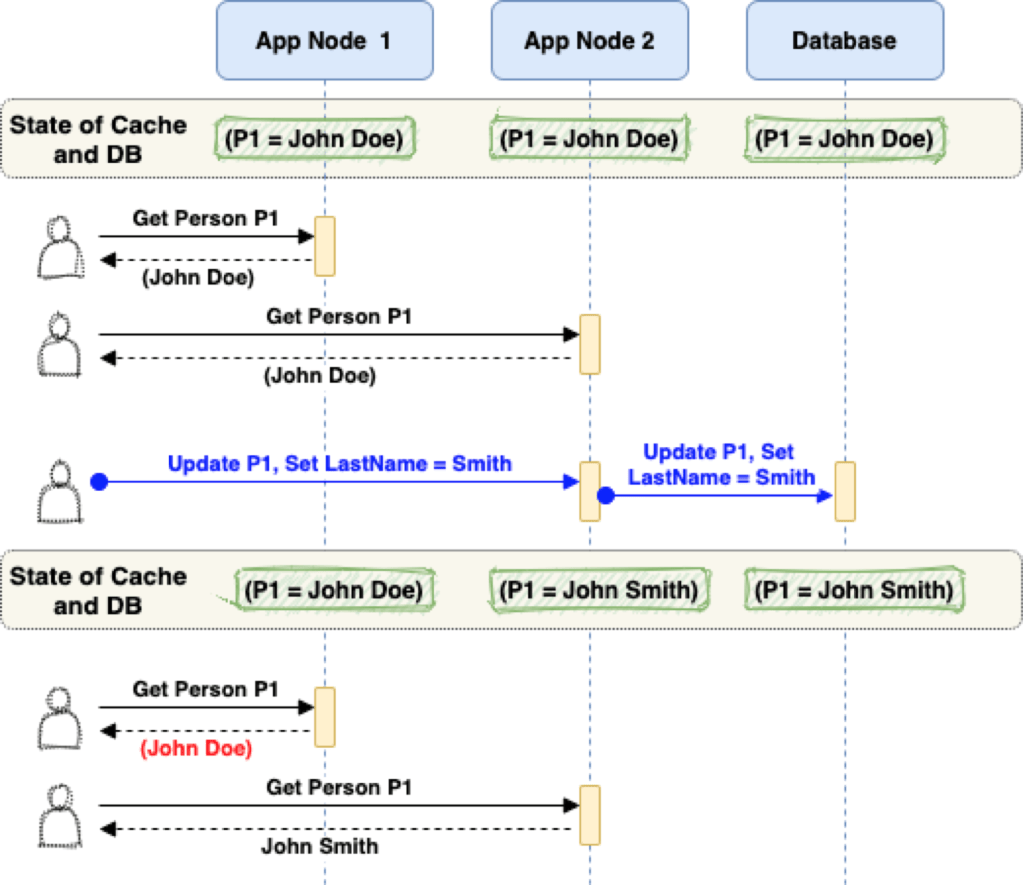
As you can see in above example, App Node 1 continues to serve the stale/old person record even after the database was updated.
2.0 How to solve the problem of distributed cache
2.1 Cache Replication for distributed embedded caches.
If the cache servers are embedded within the application, then the solution is to enable REPLICATION within these cache servers.
This means any change to any application server cache will be propagated automatically to all other application server caches.
For this to happen there has to be a DISCOVERY mechanism by which each cache server knows about the location of other cache servers.

Can you think of situations where using above cache architechture could lead to problem?
When there are huge number of replicated nodes, e.g 50-100, then the time to discover and replicate data across all such nodes will become more and more difficult and time taking.
Basically as the number of nodes will increase, so will the replication time and hence at one time it will reach a stage where replication across all nodes in real time will not be feasible.
2.2 Remote Cache Server
The other alternate solution to avoid this cache replication overhead is to use a Remote Cache server, like below
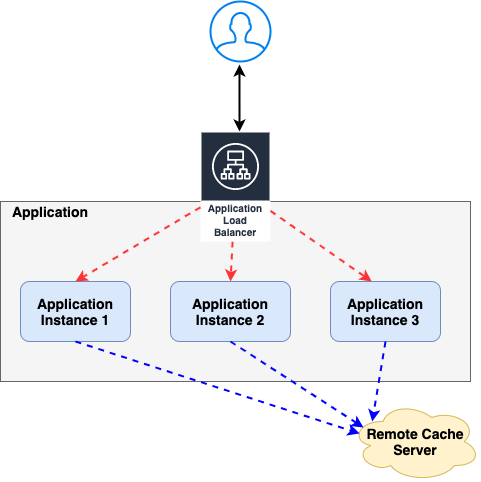
This will solve our replication latency issues.
However this not be as fast as the embedded cache – because there will be a network call to reach the cache server
3.0 Implementing Distributed Caching using HazelCast
In this section we will see how we can implement distributed caching using Hazelcast cache. We will implement an replicated embedded cache, and not a remote cache server.
The sample Spring Boot application and entire for this project can be found at – https://github.com/chatterjeesunit/spring-boot-app/tree/v8.0
To checkout this Release tag, run following command
git clone https://github.com/chatterjeesunit/spring-boot-app.git
cd spring-boot-app
git checkout tags/v8.0 -b v8.0-hazelcast-caching
3.1 Adding Dependencies & Configurations
Add following dependencies to your build.gradle
implementation 'org.springframework.boot:spring-boot-starter-cache' implementation group: 'com.hazelcast', name: 'hazelcast-all', version: '4.0.2'
Next we will enable Caching in Spring Boot using a Configuration class
@Configuration
@EnableCaching
public class CacheConfig {
}
Last but not the least, add configuration for Multicast Discovery – the way by which each embedded cache server can communicate with all other embedded cache servers in the network.
Add a file “hazelcast.yaml” in src/main/resources folder with following content.
hazelcast:
network:
join:
multicast:
enabled: true
That’s all configuration needed to configure Distributed caching in Spring Boot using Hazelcast. You can now add @Cacheable annotation to your methods and start caching your data.
3.2 Network configuration for Cache Discovery
Now in any distributed replicated architecture, all the group nodes needs a way to discover and communiate with other nodes in the same group.
We have seen in previous section we saw that we enabled Multicast discovery in hazelcast.yaml.
So the question comes – What is multicast?

In actual production environment we should replace the
multicastdiscovery with something more suited to your environment using either of the plugins below
Hazelcast Discovery Plugin for Kubernetes or
Hazelcast Discovery Plugin for AWSYou can also refer to following Hazelcast blog for reference – https://hazelcast.com/blog/how-to-use-embedded-hazelcast-on-kubernetes/
3.3 Testing it all out
In our project we already have Docker Compose set up, using which we can easily spawn more than 1 instances of the application server.
So lets start 3 nodes of application server (with embedded hazecast cache)
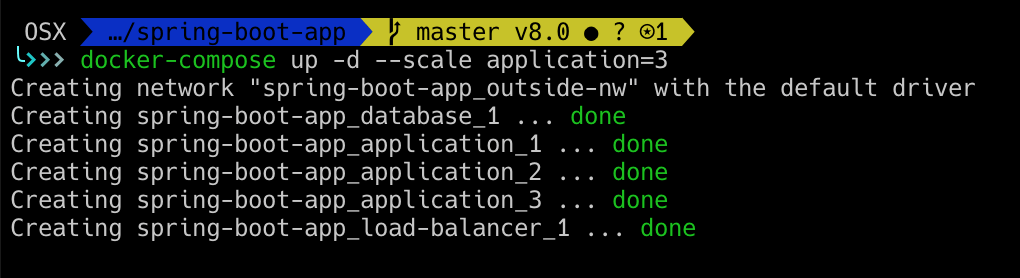
If you look at your application logs, you can see something like this

This shows that all three nodes are now connected via multicast, and are connected on port 5701.
You can now test the distributed caching, but calling read/write APIs of the application. You will notice that as soon as you call any write API, the cache of all nodes are updated automatically. Each application node will return the same updated data.
With this we come to end of this blog on building Distributed Hazelcast caching with Spring Boot Application.

Couldn’t have been explained better in such simplified format. Thank you.
LikeLiked by 1 person
Hi, Are you sure whether every write is stored in all the members of hazlecast? As per my understanding the data goes only the primary and back up member not to all. Say there are 3 members and there are 30 records of data. It splits the data into 3 equal parts like D1 (1-10 records) , D2 (11-20) and D3 (21-30). Fist member holds D1 and back up for D2 , 2nd Member holds D2 and Back up for D3, 3rd member holds D3 and back up D1. If it is not storing in this way, there is no horizontal scale up for this framework..
LikeLike
Yes, what you are saying might be true… Generally in any distributed environment the data is partitioned and replicated across nodes (similar to the example you gave). However I have not deep dived into how hazelcast stores the data so I would not be able to comment on it. Spring boot provides a good abstraction to the caching so all those details are hidden from the user. What I wanted to emphasise was that the data is replicated across the cache and no matter which cache node you access you will get correct data from the cache
LikeLike