
Apache Cassandra is an open source NoSQL distributed database and is highly scalable. In this blog, we will take a high level look at Cassandra and how is it different from traditional RDBMS (MySQL, Postgres, etc) and also from other document databases like MongoDB.
1.0 How is data stored differently in Cassandra?
- Cassandra is not a relational database, which means
- no relationships between tables.
- no joins in queries.
- data is completely de-normalized.
- However it is also not similar to other document based NoSQL databases like
MongoDB– as it still stores in data in tables and not in document structure
Let us see few examples to understand it better.
Let’s take an example of catalog of books and its reviews – and then understand how the data storage schema will vary across different types of databases.
1.1 Data model in traditional RDBMS
Lets first see how we would do it in traditional RDBMS (e.g. Postgres, MySQL, etc)
The main driving factors for table design in RDBMS are
- Table relationships are the primary criteria that defines a table structure
- Data is completely
normalizedto avoid redundancy of data - How we query the data is not considered that much during table design.
In RDBMS we will create normalized tables like this

bookstable will have data for all booksreviewerstable will have data for all the reviewersbook_reviewswill have data for all reviews for books
A sample of data in these tables would look like this

To fetch all reviews for a book or all reviews for a reviewer – we need to perform an
INNER JOINbetween these two tables
1.2 Data model in document based NoSQL DB (like MongoDB)
In document data stores like Mongo, the driving factors would be
- Entire book needs to be stored as single document
- Entire book along with reviews are fetched in a single query
- Don’t worry too much about attributes, as schema is flexible
A sample of books stored in a document db store would look like this

1.3 Data model in Cassandra
The main driving factor for schema design in Cassandra would be
- How you want to query the data – this is the most important factor
- What will be your partition key in the table
- No normalization of data
Suppose we want to do two kinds of queries with the book reviews
- Get all reviews for a given book
- Get all reviews by a particular reviewer
We will have following tables created in Cassandra to support both above queries.
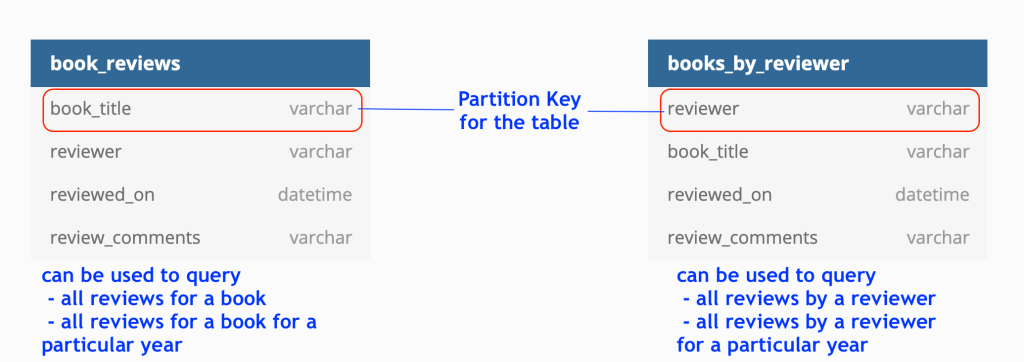
This is how sample data in both these tables would look like

In Cassandra, we can end up creating multiple tables to store same data. This is to ensure that partition keys are different and query fetch is optimized and very fast.
We will cover partition keys and data modeling in Cassandra in future blogs, that will help you understand the reason and logic behind this kind of duplicate table storage.
2.0 Distributed database
This is perhaps the biggest differentiator of Cassandra from other Relational databases.
Most relational databases
- Do not have distributed architechture build in their core architecture. Most of them generally have a separate cluster version and their default versions do not support clustering out of the box.
- Most of them function in
Master-Slaveconfiguration which leads to single point of failure of master OR performance degradation as all writes happens to master nodes and is replicated to slave nodes. - Additionally there is lot of overhead involved in setting up the clusters, maintaining it and to ensure that there is no single point of failure in such clusters.
MySQL Cluster (NDB) provides distributed database with asynchronous replication and automatic sharding (based on primary key).
Most NoSQL database are however by default distributed in nature.
Cassandra is highly distributed. Some Key Features are
2.1 Single/Multi Data Center support
You can have as many nodes in the cluster as you want – data will be distributed across the clusters.
Additionally Cassandra nodes can be spread across a single Data Center or even multiple Data Centers.

2.2 All nodes are equal
- All Nodes are Equal
- There is no master-slave configuration – which means all nodes are treated equally in the cluster
- Each node talk to other nodes using
Gossipprotocol - Each node can handle read or write requests

2.3 Self Healing
- Hinted Handoff
- Whenever there is a write request, and if some node is not available for write then data on that node can become inconsistent.
- In this case the write’s coordinator node preserves the data to be written as a set of hints.
- When the unavailable node comes back online, the co-ordinator node then effects repair by providing hints so that the node can catch up on all pending writes.

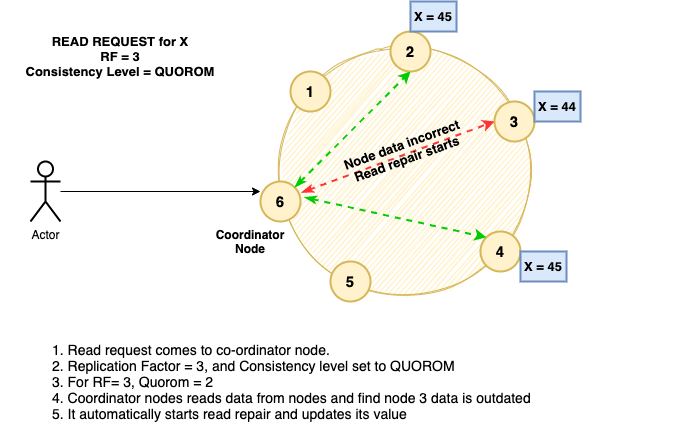
In above example we can see that
- There is write requests to co-ordinator node #17.
It is able to write to the value59to two of the nodes, but third replication node is down currently.
Coordinator nodes saves the value aHint - Third node comes back up – and its current value is
83. It gets hints from coordinator nodes, and find alldaCoordinator node send theHintto the third node now. - Third node repairs itself to latest value of
59
- Read Repair
- Read also happens from many nodes.
- If the co-ordinator nodes finds that one of the read-node’s data is inconsistent it automatically provides it with most recent version of data.
2.4 Easy Setup
- No additional configuration required like separate config servers or zookeeper nodes, etc.
- Can be easily setup on any cluster or datacenter
2.5 Fault Tolerant
- Most cassandra nodes are replication (standard recommended
RF=3) - This ensures Cassandra cluster can keep working even if there are faults.

2.6 Deployment Agnostic
- Cassandra cluster can be deployed on AWS, Azure, GCP or even on on-premise cluster.
- We can even have each cluster deployed on different stack.

3.0 Highly Scalable
3.1 Vertical Scaling vs Horizontal Scaling

Vertical scaling
- Involves increase the CPU / RAM of machines – buy more and more powerful machines
- Gets costly very soon
- Scaling might involve downtime, as a machine is replace with more powerful machine
- There is a limit to which we can scale
Horizontal Scaling
- Also known as elastic scaling
- We can do both
- scale-up – increase more and more machines to share load
- scale-down – decrease machines as load decreases
Traditional RDBMS generally scale vertically.
The cluster version of most RDBMS might scale horizontally, but most of them are only able to scale the # of reads. They do not scale the # of writes very easily.
3.2 How does Cassandra handles scaling?
Why do most traditional RDBMS do not scale
- Complex relation tables and multiple
joinsto fetch data – resulting in slower queries - Most master-slave configurations can scale reads, but are not able to scale writes (while maintaining
ACIDproperties). - As data grows, they may have to
shardthe data – which brings additional complexities- cannot perform
joinsacross shards. - cannot fetch data from multiple shards.
- aggregation queries do not work across shards.
- schema changes are difficult to propage across shards.
- need a very good consistent hashing mechanism to ensure that lot of data is not moved around when nodes are added/removed.
- cannot perform
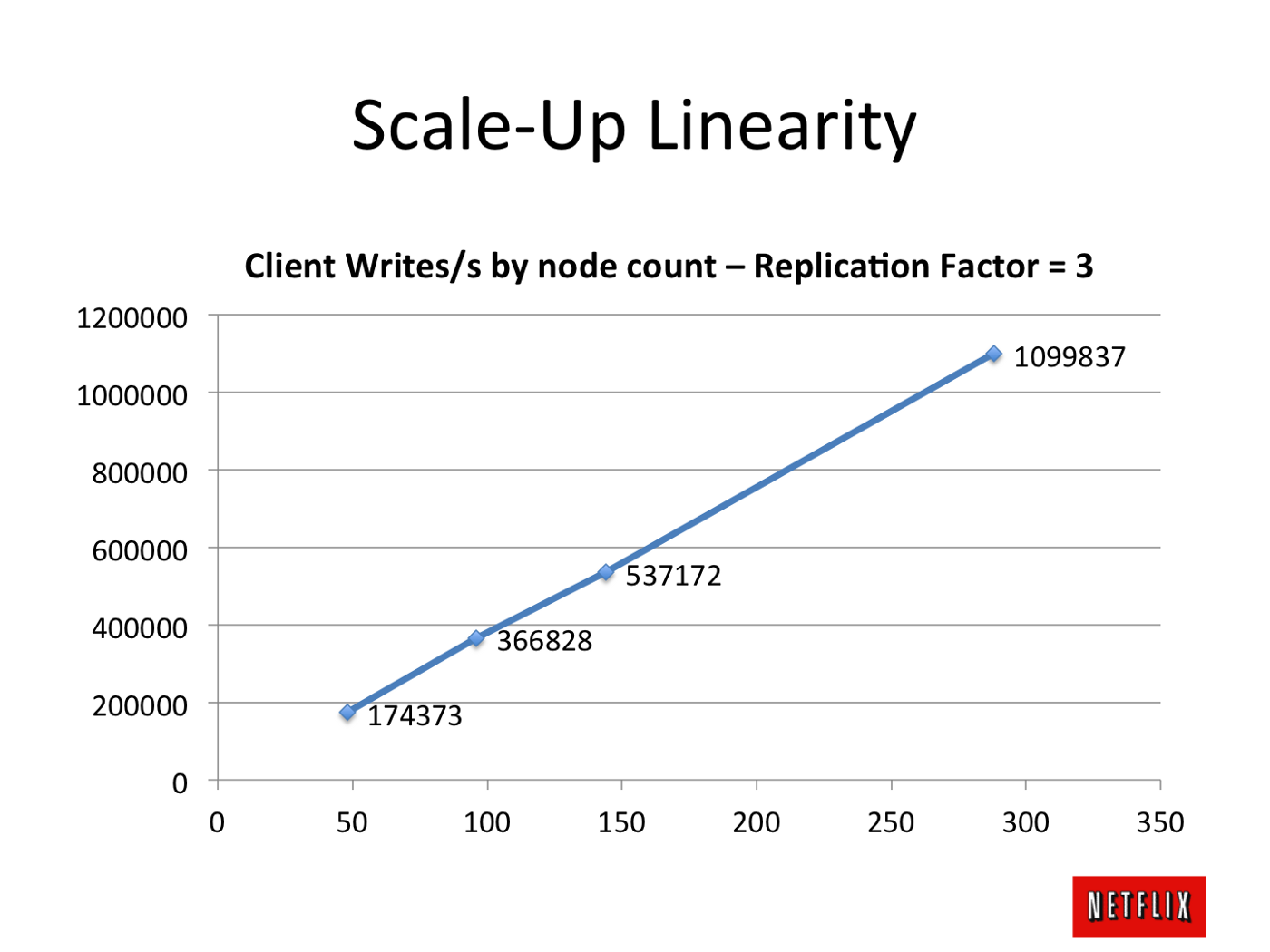
Cassandra scales LINEARLY
- This means if you are getting
Xread/write request per second with 10 nodes. - Then if you add another 10 nodes, you will get
2Xread/write request per second. - All nodes are equal in cassandra and we can add new nodes without any downtime.
- Cassandra does not supports sharding, but partitions the data.
- The data modelling is done based on queries – to ensure reads are very fast and without joins
Even though Cassandra is highly distributed and scalable database, it is in no way a replacement for traditional databases. RDBMS may be suited for many small to medium applications and will be able to handle the load extremly well.
It is always recommended that before choosing any database, we should always identify our requirements, load, scalability requirements and then make a decision on which database to choose.
In our future blogs we will cover additional topics for Cassandra like partitions, CQL, data modeling, etc.

Very nice .
LikeLike