
Partitions is a core feature of Cassanda, that controls how data is stored and queried from a multiple node Cassandra cluster. In this blog we will deep dive into the internals of Cassandra Partitions.
What are Partitions
In Cassandra each table is broken up into multiple partititions – which are then stored in different nodes of the cluster.
- All data for a single partition always resides on a one node.
- Data of a partition is never spread across multiple nodes.
- This is important, as we won’t have to visit multiple nodes to fetch partition data
- When you query for any data in Cassandra, the query must specify the value of the partition key.
- Each partition contains of multiple rows of data (that are grouped together by a partition key)
A Very Simple View of how data is partitioned.
Suppose we have this 10 rows of books data that we want to store in Cassandra table called books
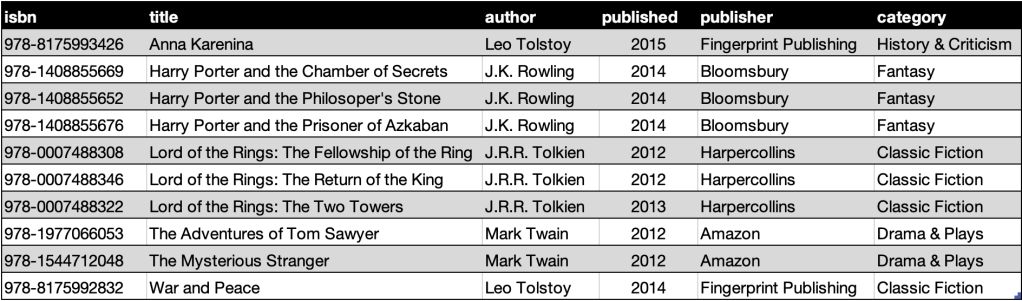
- We want to store this data in a 3 node Cassandra cluster
- Lets assume our
Partitioning Keyfor thisbookstable isauthorcolumn.
This is how partitioning works typically

Let us understand what just happened above
- Cassandra cluster has 3 nodes, with replication factor of 1 – which means no replication of data (just assume this for sake of simplicity)
- Each node can handle a range of tokens
- Node N1 – tokens 0 – 25
- Node N2 – tokens 25 – 50
- Node N3 – tokens 51 – 75
- Now when we try to save this 10 rows of data in Cassandra – it first fetches the
partition keyfor each row, which is theauthorcolumn
- A consistent hashing algorithm is applied to the value in
authorcolumn to generate thetoken. e.g.- Leo Tolstoy -> Token = 63
- J.K. Rowling -> Token = 21
- Mark Twain -> Token = 5
- J.R.R. Tolkien -> Token = 51
- For each row of data, the partition key is used to generate the token. Then based on the token range of nodes, the data is stored on respective nodes. e.g.
- Node N1
- J.K. Rowling – all 3 rows
- Mark Twain – all 2 rows
- Node N2
- J.R.R. Tolkien – all 3 rows
- Node N3
- Leo Tolstoy – all 2 rows
- Node N1
This principle of data storage – where all data for a given partition is always stored on a specific node, is also responsible for the fast read response in Cassandra.
Based on the value of partition key in the query, Cassandra will always know from which node it needs to fetch the data. It does not have to go and look into each node for the query results.
How the choice of partition key impacts data storage
Choice of partition key is very important in table design in Cassandra – the reason being it CANNOT be changed once a table is created.
Let’s see some examples of how data gets partitioned, based on the choice of paritition key.
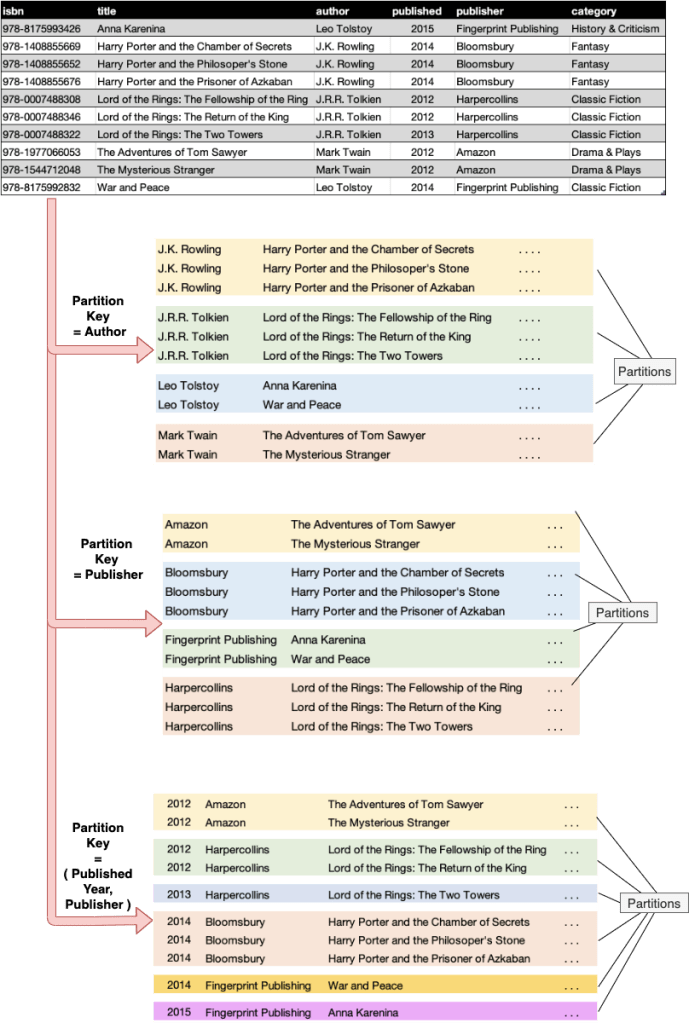
As we have seen in above example, a partition key does not always needs to be decided from one column. Multiple columns can help in deciding the partition key. e.g. in last example above, the published year and publisher together creates a composite partition key.
A wrong paritition key choice such could lead to either the parition being too small (1 row partitions), or the partition being so big that it cannot fit in one node.
e.g. if in above books example
- partition key =
isbn- each partition will have only 1 row, since
isbnis unique - querying books will always require you to specify
isbnas the primary query condition
- each partition will have only 1 row, since
- partition key =
publisher- if the publisher is a quite popular one and publishes thousands of books every year, then with time this partition will keep on growing and become very huge.
- A simple solution would be to add
published yearto the parition key, as shown in example above.
Partitions and tokens in a real cluster
In the examples that we saw above, we used RF of 1 for simplicity and also showed token ranges in very low ranges (less than 100).
In real production clusters
Replication Factorwould generally be 3.- Tokens are generally in range of
-2^63to+2^63 -1. - Each node will be assigned multiple token ranges via
Vnodes

- In above example we have a
8node cluster, with aRF = 3. - We first hash the key to generate the
token. - We “walk” the ring in a clockwise fashion until we encounter three distinct nodes, at which point we have found all the replicas of that key.
- e.g.
- For Key =
foo- Hash is between
t1andt2 - So replicas for this key, are next three nodes
n2,n3,n4
- Hash is between
- For Key =
bar- Hash is between
t2andt3 - So replicas for this key, are next three nodes
n3,n4,n5
- Hash is between
- For Key =
Live demo – tokens and partitions
Lets create a 3 node cluster on our local system (for now with RF = 1)
We will use
Casandra:3.11docker image to run our local Cassandra cluster.
Create Network
# create network
docker network create cassandra-network
# create first node
docker run \
--network cassandra-network \
--name cassandra-node1 \
-e MAX_HEAP_SIZE=1G \
-e HEAP_NEWSIZE=256M \
-d cassandra:3.11
# create second node
docker run \
--network cassandra-network \
--name cassandra-node2 \
-e MAX_HEAP_SIZE=1G \
-e HEAP_NEWSIZE=256M \
-e CASSANDRA_SEEDS=cassandra-node1 \
-d cassandra:3.11
# create third node
docker run \
--network cassandra-network \
--name cassandra-node3 \
-e MAX_HEAP_SIZE=1G \
-e HEAP_NEWSIZE=256M \
-e CASSANDRA_SEEDS=cassandra-node1,cassandra-node2 \
-d cassandra:3.11
Once you run this you will have 3 node cluster up and running.
Note: Please wait few seconds between running each command above. This will ensure the nodes have some to get up and running, before starting another node.
Lets verify the cluster status, by running nodetool status
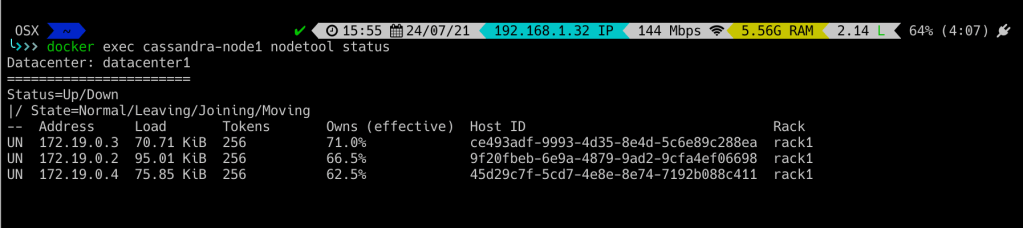
Now lets create some keyspace and tables. Open CQLSH and run below commands to create tables and insert data into it.
- Create a keyspace
demo_kswithRF=1
CREATE KEYSPACE demo_ks
WITH replication = {
'class':'SimpleStrategy',
'replication_factor': 1
};- Create a table
books_by_author
USE demo_ks;
CREATE TABLE books_by_author (
author text,
title text,
isbn text,
published_year int,
publisher text,
category text,
PRIMARY KEY((author), title, isbn));- Insert books data into the table
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-8175993426','Anna Karenina','LeoTolstoy',2015,'Fingerprint Publishing','History & Criticism');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-1408855669', 'Harry Porter and the Chamber of Secrets', 'J.K.Rowling', 2014, 'Bloomsbury', 'Fantasy');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-1408855652', 'Harry Porter and the Philosoper''s Stone', 'J.K.Rowling', 2014, 'Bloomsbury','Fantasy');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-0007488308', 'Lord of the Rings: The Fellowship of the Ring', 'J.R.R.Tolkien', 2012, 'Harpercollins', 'Classic Fiction');
insert into books_by_author (isbn, title, author, published_year, publisher, category)
values ('978-1408855676', 'Harry Porter and the Prisoner of Azkaban', 'J.K.Rowling', 2014, 'Bloomsbury','Fantasy');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-0007488346', 'Lord of the Rings: The Return of the King', 'J.R.R.Tolkien', 2012, 'Harpercollins', 'Classic Fiction');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-0007488322', 'Lord of the Rings: The Two Towers', 'J.R.R.Tolkien', 2013, 'Harpercollins', 'Classic Fiction');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-1977066053', 'The Adventures of Tom Sawyer', 'MarkTwain', 2012, 'Amazon', 'Drama & Plays');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-1544712048', 'The Mysterious Stranger', 'MarkTwain', 2012, 'Amazon', 'Drama & Plays');
insert into books_by_author(isbn, title, author, published_year, publisher, category)
values ('978-8175992832', 'War and Peace', 'LeoTolstoy', 2014, 'Fingerprint Publishing', 'Classic Fiction');
Now that we have created the data, lets view the token for the partition key (author)
Open cqlsh and use the token clause to get the token for the partition key
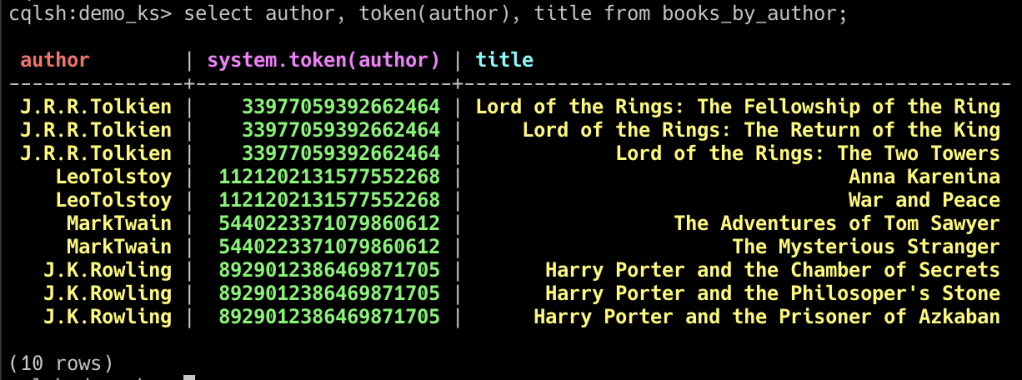
As you can see the token for rows are same, when the author is same.
This token is used by cassandra to distribute partition data across nodes.
Now let us see which node got which partition data, by running nodetool getendpoint 'keyspace' 'table' 'partition key'
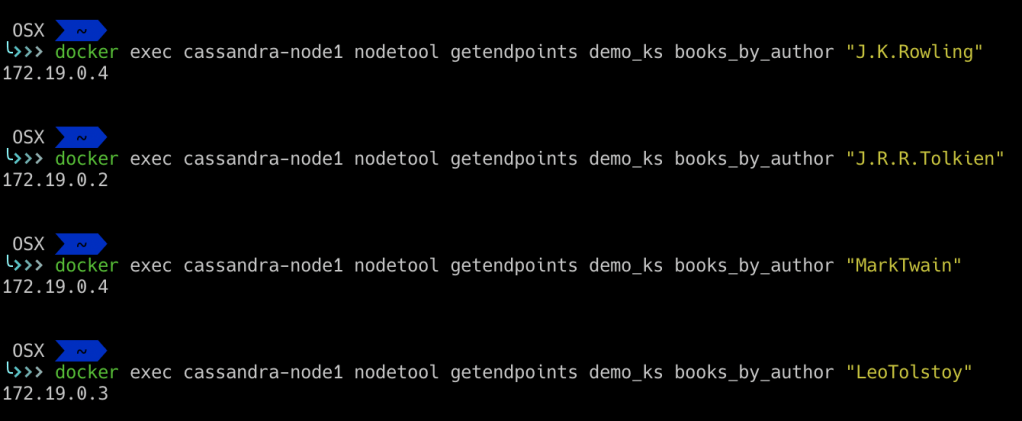
With this we come to end of this blog. In next blog we will see how to specify partition key and understand uses of partition vs clustering keys
